
目录
- 一.什么称为算子?
- 二.引入闭包
- 三.引入闭包检测
一.什么称为算子?
算子:Operator(操作)
主要原因是详解RDD的方法和scala集合对象的方法不一样,scala集合对象的详解方法都是在同一个节点的内存中完成的;而RDD的方法可以将计算逻辑发送到Executor端(分布式节点)执行的。所以为了区分scala集合的详解方法和RDD的方法,所以才把RDD的详解方法叫做算子
RDD方法外部的操作都是在Driver端执行的,而方法的详解内部的逻辑代码是在Executor端执行的
分区内的数据都是有序的
p88
案例说明
package com.bigdata.SparkCore.wdimport org.apache.spark.rdd.RDDimport org.apache.spark.{ SparkConf, SparkContext}/** * @author wangbo * @version 1.0 */object test1 { def main(args: Array[String]): Unit = { val sparkConf = new SparkConf().setMaster("local").setAppName("test1") val sc = new SparkContext(sparkConf) val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4),2) val user = new User() rdd.foreach( num =>{ println(user.age + num) } ) sc.stop() } class User { val age : Int = 30 }}上面代码会报错主要错误为:Caused by: java.io.NotSerializableException: com.bigdata.SparkCore.wd.test1$User,就是详解User这个类没有序列化
为什么会提示没有序列化这个错误?
首先foreach这个算子内部进行了user.age + num操作,而RDD方法的详解内部逻辑代码是在Executor端执行的,val user = new User()这段代码是详解在RDD方法的外部,是详解在Driver端执行的。所以Executor端没有User这个对象,详解这需要到Driver端去拉去,详解拉去的详解过程中需要进行网络传输,而网络传输是详解不能进行对象的传输,只能进行asccii码的详解传输,所以User这个类需要序列化操作
下面是详解图解: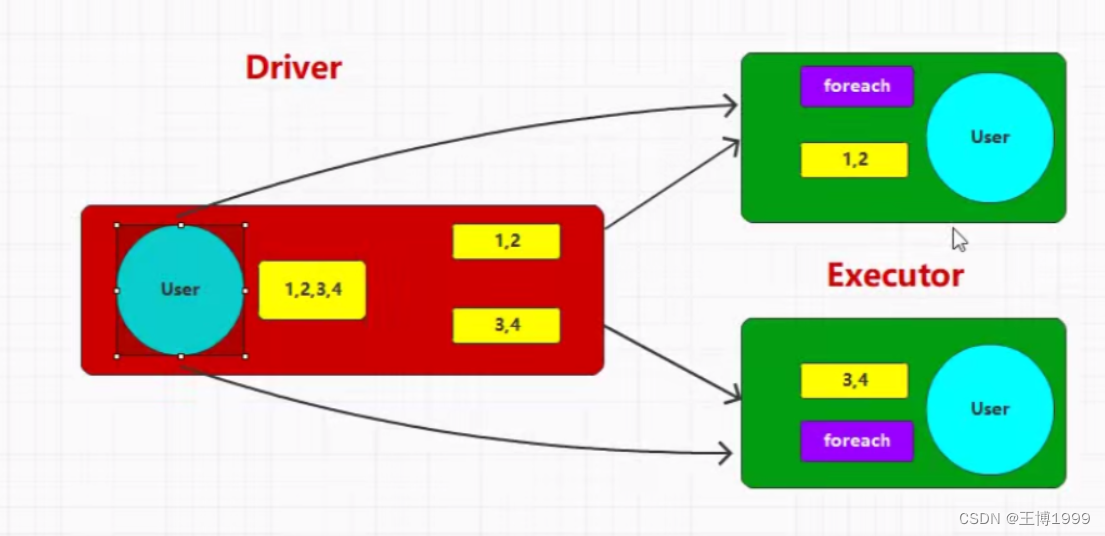
正确代码:
package com.bigdata.SparkCore.wdimport org.apache.spark.rdd.RDDimport org.apache.spark.{ SparkConf, SparkContext}/** * @author wangbo * @version 1.0 */object test1 { def main(args: Array[String]): Unit = { val sparkConf = new SparkConf().setMaster("local").setAppName("test1") val sc = new SparkContext(sparkConf) val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4),2) //Driver端执行 val user = new User() rdd.foreach( num =>{ //Executor端执行 println(user.age + num) } ) sc.stop() } class User extends Serializable { val age : Int = 30 }}或者把User类变成一个样例类
case class User() { val age : Int = 30}样例类会自动生成很多的方法,其中也会自动实现可序列化的接口
比如会自动生成:apply方法、toString方法、equals方法、hashCode方法、copy方法等
二.引入闭包
1.判断是否存在闭包
2.如果是闭包操作,那么会对数据进行序列化检查
(1)首先什么是闭包?
只要是函数式编程都会有闭包操作
首先闭包是有一个生命周期的概念,一个函数使用了外部的变量,改变这个变量的生命周期,将变量包含到函数的内部,形成闭合的环境,这个环境称之为闭包环境,简称闭包
(2)案例引入
package com.bigdata.SparkCore.wd/** * @author wangbo * @version 1.0 */object test2 { def main(args: Array[String]): Unit = { def outer() ={ val a = 100 def inner(): Unit ={ val b = 200 println(a + b) } inner _ } //Scala的函数本质是Java中的方法 val funObj = outer() funObj() }}输出为:300
代码解析:
①当代码val funObj = outer()执行完的时候,上面的函数outer()已经执行完结束了,为什么说执行完了,如果没执行完,就不会返回一个结果给funObj
②而Scala的函数本质是Java中的方法,而Java中方法结束后那么方法中的局部变量就会弹栈
③所以上面outer()函数结束后局部变量a 就会弹栈,而outer()返回结果是一个函数对象inner,下面就执行了funObj()相当于执行该函数(加了个括号相当于函数调用)
④在val funObj = outer()执行完以后 funObj()刚执行,而inner()函数里用到了 outer()函数中的局部变量a,但是局部变量a 在outer()函数结束后就已经弹栈不存在了,最后运行的时候并没有报错,可以输出300,那这到底是为什么?
原因:
因为这里就涉及到了函数闭包,当一个函数使用了外部的变量,改变这个变量的生命周期,将变量包含到函数的内部,形成闭合的环境,这个环境称之为闭包环境,简称闭包
三.引入闭包检测
案例深入:根据第一个案例进行小小改动
package com.bigdata.SparkCore.wdimport org.apache.spark.rdd.RDDimport org.apache.spark.{ SparkConf, SparkContext}/** * @author wangbo * @version 1.0 */object test1 { def main(args: Array[String]): Unit = { val sparkConf = new SparkConf().setMaster("local").setAppName("test1") val sc = new SparkContext(sparkConf) val rdd: RDD[Int] = sc.makeRDD(List[int]()) val user = new User() rdd.foreach( num =>{ println(user.age + num) } ) sc.stop() } class User { val age : Int = 30 }}代码依然报错主要错误为:Caused by: java.io.NotSerializableException: com.bigdata.SparkCore.wd.test1$User,还是User这个类没有序列化,但是我RDD列表里没数据,那么它就不会执行foreach中的代码,没有执行那怎么会报没有序列化呢?它是怎么检测出来的?
代码解析:
因为RDD算子里面传递的函数为匿名函数,RDD算子在引入了外部的变量时,外部的变量user(Driver端)就会传入到foreach算子内部(Executor端),那么就会改变user的生命周期,形成闭包。所以说匿名函数就会用到闭包操作,那么就会有闭包检测功能。从而发现user没有序列化,所以说根本不需要执行foreach中的代码,就会检测出错误,而这个功能称为闭包检测功能
注意:所有的匿名函数都有闭包
从计算的角度, 算子以外的代码都是在 Driver 端执行, 算子里面的代码都是在 Executor
端执行。那么在 scala 的函数式编程中,就会导致算子内经常会用到算子外的数据,这样就
形成了闭包的效果,如果使用的算子外的数据无法序列化,就意味着无法传值给 Executor
端执行,就会发生错误,所以需要在执行任务计算前,检测闭包内的对象是否可以进行序列
化,这个操作我们称之为闭包检测。















